Motivation
TL;DR;
Reducing ① the memory overhead of key-value cache
and ② activation memory during training.
This post we mainly discuss on ①.
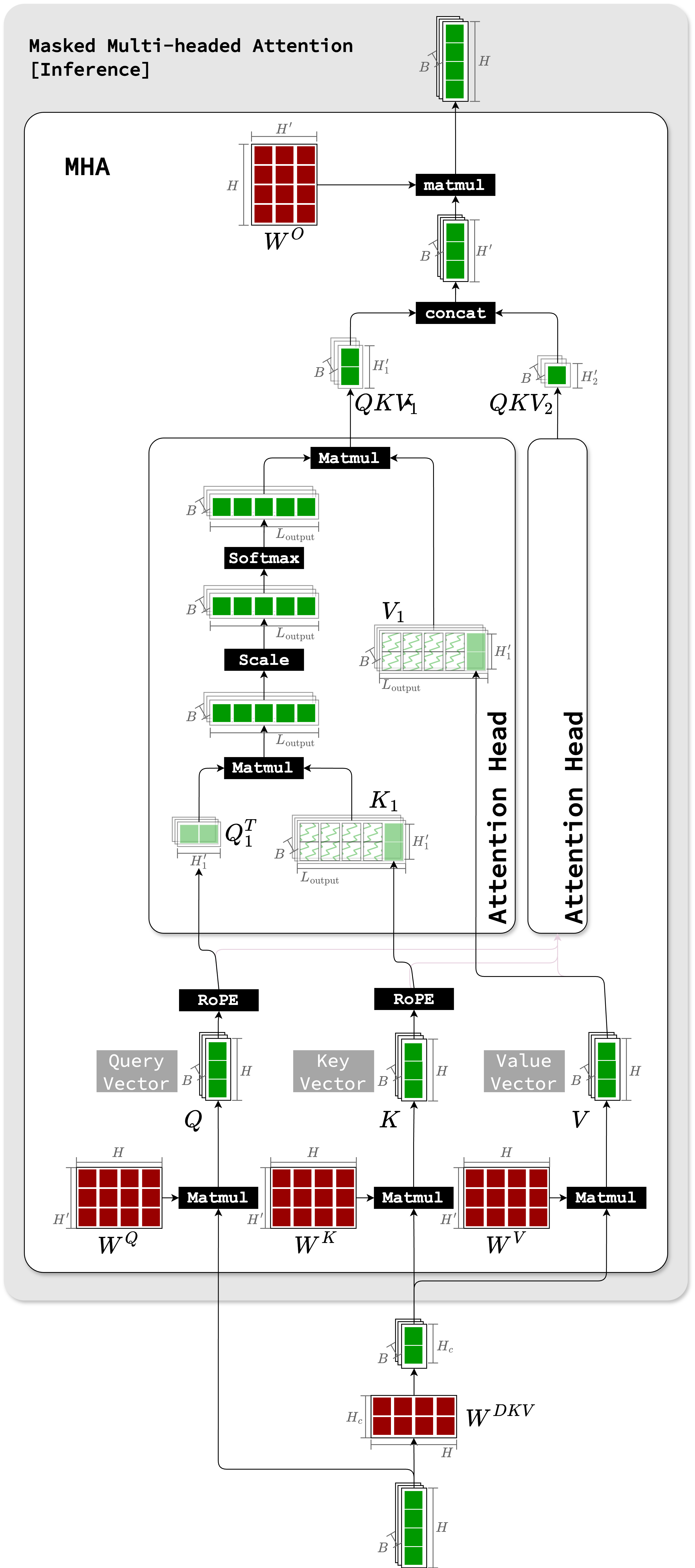
Recall MHA
Multi-head Latent Attention (MLA) aims at compressing key-value cache generated during inference.
Recall the attention head of Multi-Head Attention (MHA),
let's look at the masked MHA layer in the decoder block
(i.e., first MHA layer in the decoder block):
Firstly the decoder should calculate the query, key and value of current token,
based on its hidden embedding $h_t$:
$q_t = W^Qh_t\,\,\,\,k_t = W^Kh_t\,\,\,\,v_t = W^Vh_t$
And the output of the MHA block is calculated by:
$$
u_t =
W^O \times
\sum^{t}_{j=1} \left[
\underbrace{
\texttt{Softmax}(
\frac{
q_t^T
\times
k_j
}{
\sqrt{n_h d_h}
}
)
}_{\texttt{Attention Score}}
\times
v_j
\right]
$$
where $n_h$ is the number of attention heads,
$d_h$ is the dimension of query/key/value vectors within one attention head.
The key and value of tokens that before current token are stored in the KV-cache (i.e., $\{k_j, v_j | j \le t\}$),
and the key and value of the current token would be appended to the KV-cache for calculation of subsequent tokens.
Hence,
the overall size of the KV-cache is shown in mha_kvc_size,
where $n_{\text{decoder}}$ is the number of decoder block in the model,
and $\mathcal{L}_{\text{output}}$ is the length of the output tokens.
$2 \times n_{\text{decoder}} \times n_h \times d_h \times \mathcal{L}_{\text{output}}$
Memory Overhead of KV-cache
Let's do some napkin math here.
For DeepSeek-V2, which adopts $n_{\text{decoder}}=60$ and $n_h \times d_h=5120$.
The size of KV-cache with different precision and context length is shown in mha_kvc_size:
MLA Process
Basic Idea
To address the explosion of KV-cache size with context length,
The core of MLA is to compress the key $k_t$ and value $v_t$ of every decoded token
into one single latent vector $c^{KV}_t$,
which could save the memory overhead of KV-cache with a factor of $\frac{2d_h}{d_c}$.
The decoder restores the original key $k_t$ and value $v_t$ from $c^{KV}_t$ during decoding.
Formally, $c^{KV}_t$, $k_t$ and $v_t$ are calculated by:
$$
c^{KV}_t = W^{DKV}h_t,
\,\,\,\,
k_t = W^{UK}c^{KV}_t,
\,\,\,\,
v_t = W^{UV}c^{KV}_t
$$
Combine c_kv and mha,
one can see $W^{UK}$ and $W^{UV}$ could be absorbed into $W^Q$ and $W^O$ respectively,
as shown in absorb:
$$
\begin{aligned}
u_t
&= W^O
\sum^{t}_{j=1} \left[
\underbrace{
\texttt{Softmax}(
\frac{
\overbrace{[W^Qh_t]^T}^{\texttt{query}}
\overbrace{W^{UK}c^{KV}_t}^{\texttt{key}}
}{
\sqrt{n_h d_h}
}
)
}_{\texttt{Attention Score}}
\overbrace{W^{UV}c^{KV}_t}^{\texttt{value}}
\right] \\ \\
&= W^O
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
h^T_t
\overbrace{[W^Q]^TW^{UK}}^{\texttt{merge}}
c^{KV}_t
}{
\sqrt{n_h d_h}
}
)
W^{UV}c^{KV}_t
\right] \\ \\
&= W^O
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
h^T_t
[W_{\text{merged}}^Q]^T
c^{KV}_t
}{
\sqrt{n_h d_h}
}
)
W^{UV}c^{KV}_t
\right] \\ \\
&= \underbrace{W^O W^{UV}}_{\texttt{merge}}
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
h^T_t
[W_{\text{merged}}^Q]^T
c^{KV}_t
}{
\sqrt{n_h d_h}
}
)
c^{KV}_t
\right] \\ \\
&= W^O_{\text{merged}}
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
h^T_t
[W_{\text{merged}}^Q]^T
c^{KV}_t
}{
\sqrt{n_h d_h}
}
)
c^{KV}_t
\right] \\ \\
\end{aligned}
$$
Compatible with RoPE
However, our above calculation doesn't introduce
Rotary Position Embedding (RoPE) into account,
which would integrate position information into the query and key vector after projecting from token embedding.
Let' see what happen if we directly combine latent key-value vectors with RoPE,
as shown in mha_rope:
$$
\begin{aligned}
u_t &=
W^O \cdot
\sum^{t}_{j=1} \left[
\underbrace{
\texttt{Softmax}(
\frac{
[\texttt{RoPE}_t(q_t)]^T
\cdot
\texttt{RoPE}_j(k_j)
}{
\sqrt{n_h d_h}
}
)
}_{\texttt{Attention Score}}
\cdot
v_j
\right] \\ \\
&=
W^O \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
[R_t \cdot q_t]^T
\cdot
R_j \cdot k_j
}{
\sqrt{n_h d_h}
}
)
\cdot
v_j
\right] \\ \\
&=
W^O \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
[R_tW^{Q}h_t]^T
\cdot
R_jW^{UK}c_t^{KV}
}{
\sqrt{n_h d_h}
}
)
\cdot
W^{UV}c_t^{KV}
\right] \\ \\
&=
W^O \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
h^T_t[W^{Q}]^TR^T_t
\cdot
R_jW^{UK}c_t^{KV}
}{
\sqrt{n_h d_h}
}
)
\cdot
W^{UV}c_t^{KV}
\right] \\ \\
&=
W^O \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
h^T_t
\overbrace{[W^{Q}]^TR_{t-j}W^{UK}}^{\texttt{can't merge}}
c_t^{KV}
}{
\sqrt{n_h d_h}
}
)
\cdot
W^{UV}c_t^{KV}
\right] \\ \\
\end{aligned}
$$
We can see that there's a position-sensitive rotation matrix $R_{t-j}$ sits between $W^{Q}$ and $W^{UK}$,
which causes the $W^{UK}$ can't be absorbed into $W^{Q}$.
If we let it go,
this would force us to recalcuate the key of every previous token before the current generated token,
which causes tremendous calculation overhead.
TL;DR;
The calculation process of $\texttt{RoPE}$ on vector $q_t \in [1, d_h]$ is a matrix operation of
$q_{\text{rotated}} = q \cdot R(m)$
Below we infers the calculation process in details.
Rotate a Vector
Recall that $\texttt{RoPE}$ splits the processed vector $q_t$ into $\frac{q_t}{2}$ parts,
each part represent a pair of complex numbers.
For the $i^{\text{th}}$ pair, $\texttt{RoPE}$ construct a $2\times2$ rotation matrix $R_i(m)$,
as shown in R_i.
$$
R_i(m) =
\begin{bmatrix}
\cos(m \omega_i) & -\sin(m \omega_i) \\
\sin(m \omega_i) & \cos(m \omega_i)
\end{bmatrix}
$$
where $\omega_i = \frac{1}{10000^{\frac{i}{d_h}}}$, and $m$ is the position index.
Arrange all $R_i$ along the diagonal to form a $d_h\times d_h$ matrix $R(m)$,
as shown in R.
$$
R(m) =
\begin{bmatrix}
R_0(m) & 0 & \cdots & 0 \\
0 & R_1(m) & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & R_{\frac{d_h}{2}-1}(m) \\
\end{bmatrix}
$$
Suppose we are given the vector $q_t$ with $d_h=4$, i.e., $q_t = [q_0, q_1, q_2, q_3]$,
the rotated vector $q_{\text{rotated}}$ is calculated by:
$$
\begin{aligned}
q_{\text{rotated}}
&= R(m) \cdot q_t \\ \\
&=
\begin{bmatrix}
R_0(m) & 0\\
0 & R_1(m)\\
\end{bmatrix}
\cdot
\begin{bmatrix}
q_0 \\ q_1 \\ q_2 \\ q_3
\end{bmatrix} \\ \\
&=
\begin{bmatrix}
sin(m \omega_0) & -cos(m \omega_0) & 0 & 0 \\
sin(m \omega_0) & -cos(m \omega_0) & 0 & 0 \\
0 & 0 & sin(m \omega_1) & -cos(m \omega_1) \\
0 & 0 & sin(m \omega_1) & -cos(m \omega_1) \\
\end{bmatrix}
\cdot
\begin{bmatrix}
q_0 \\ q_1 \\ q_2 \\ q_3
\end{bmatrix} \\ \\
&=
\begin{bmatrix}
q_0 \cos(m \omega_0) - q_1 \sin(m \omega_0) \\
q_0 \sin(m \omega_0) + q_1 \cos(m \omega_0) \\
q_2 \cos(m \omega_1) - q_3 \sin(m \omega_1) \\
q_2 \sin(m \omega_1) + q_3 \cos(m \omega_1) \\
\end{bmatrix} \\ \\
\end{aligned}
$$
Calculated Relative Position
RoPE has a nice property that it can reflect the relative position of query and key,
as shown in mha_rope_calc_relative.
$$
\begin{aligned}
q_{\text{rotated}}^T \cdot k_{\text{rotated}} &= [\texttt{RoPE}_t(q_t)]^T \cdot \texttt{RoPE}_j(k_j) \\ \\
&= [R_t \cdot q_t]^T \cdot R_j \cdot k_j \\ \\
&= q_t ^T\cdot R_t^T \cdot R_j \cdot k_j \\ \\
&= q_t ^T\cdot R_{t-j} \cdot k_j \\ \\
\end{aligned}
$$
To address this issue,
MLA adopts a simple way:
let only portion of the query/key vector to carray to position information,
i.e., don't rotate the entire query and key vector,
and cache the rotated portion of the key vector in the kv-cache.
For the query vector, the detailed calculation is shown in decoupled_rope_q,
where $W^{QR}$ is the matrix to project the latent query vector for conducting $\texttt{RoPE}$.
$$
\begin{cases}
q^C_{t} &=& W^{UQ} \cdot c_t^Q \\ \\
q^R_{t} &=& \texttt{RoPE}_t(W^{QR} \cdot c_t^Q)
\end{cases}
$$
For multiple attention heads,
the query vector is splited into multiple parts evenly,
as shown in decoupled_rope_q_i:
$q_{t} = [q_{t,1},\,q_{t,2},\,\cdots,\,q_{t,n_h}],\,\,\,\,q_{t,i} = [q^C_{t,i};\,q^R_{t,i}]$
For the key vector, thing works basically the same,
$$
\begin{cases}
k^C_{j} &=& W^{UK} \cdot \overbrace{c_j^{KV}}^{\texttt{cached}} \\ \\
k^R_{j} &=& \underbrace{\texttt{RoPE}_j(W^{KR} \cdot c_j^{KV})}_{\texttt{cached}}
\end{cases}
$$
For multiple attention heads,
one should note that the rotated portion of key vector is shared across all heads,
as shown in decoupled_rope_q_i:
$k_{j} = [k_{j,1},\,k_{j,2},\,\cdots,\,k_{j,n_h}],\,\,\,\,k_{j,i} = [k^C_{j,i};\,\underbrace{k^R_{j}}_{\texttt{shared}}]$
In this way, echo back to mha_rope,
let infer the computation process of RoCE-capatible MLA,
as shown in mla_rope:
$$
\begin{aligned}
u_{t,i} &=
W^O \cdot
\sum^{t}_{j=1} \left[
\underbrace{
\texttt{Softmax}(
\frac{
q_{t,i}^T
\cdot
k_{j,i}
}{
\sqrt{n_h d_h}
}
)
}_{\texttt{Attention Score}}
\cdot
v_{j,i}
\right] \\ \\
&=
W^O \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
[q^C_{t,i};\,q^R_{t,i}]^T
\cdot
[k^C_{j,i};\,k^R_{t}]
}{
\sqrt{n_h d_h}
}
)
\cdot
W^{UV}c_j^{KV}
\right] \\ \\
&=
W^O \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
[q^C_{t,i}]^T \cdot k^C_{j,i} + [q^R_{t,i}]^T \cdot k^R_{j}
}{
\sqrt{n_h d_h}
}
)
\cdot
W^{UV}c_j^{KV}
\right] \\ \\
& \texttt{below we omit the attention head index}\,\,\,\,i \\ \\
&=
W^O \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
[W^{UQ} W^{DQ} h_t]^T \cdot W^{UK}c_j^{KV} + [\texttt{RoPE}_t(W^{QR} \cdot W^{DQ} h_t)]^T \cdot k^R_{j}
}{
\sqrt{n_h d_h}
}
)
\cdot
W^{UV}c_j^{KV}
\right] \\ \\
&=
\overbrace{W^O W^{UV}}^{\texttt{merge}} \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
[W^{DQ} h_t]^T \cdot \overbrace{[W^{UQ}]^T W^{UK}}^{\texttt{merge}} \cdot c_j^{KV}
+ [\texttt{RoPE}_t(W^{QR} \cdot W^{DQ} h_t)]^T \cdot k^R_{j}
}{
\sqrt{n_h d_h}
}
)
\cdot
c_j^{KV}
\right] \\ \\
&=
W^O_{\texttt{merged}} \cdot
\sum^{t}_{j=1} \left[
\texttt{Softmax}(
\frac{
[W^{DQ} h_t]^T \cdot W^{Q}_{\texttt{merged}} \cdot c_j^{KV}
+ [\texttt{RoPE}_t(W^{QR} \cdot W^{DQ} h_t)]^T \cdot k^R_{j}
}{
\sqrt{n_h d_h}
}
)
\cdot
c_j^{KV}
\right] \\ \\
\end{aligned}
$$
mla illustrates the computation process of MLA.
Memory Overhead of KV-cache
Observing mla_rope,
we can see that the vectors that MLA needs to cache is
-
Rotated key portion ${k_j^R,\,j\in[0,\mathcal{L}_{\text{output}}]}$
-
Latent kv-cache ${c_j^{KV},\,j\in[0,\mathcal{L}_{\text{output}}]}$
Assuming the size of $k_j^R$ is $d^R_h$,
and the size of $c_j^{KV}$ is $d_c$,
then we can know that the overall cache size of MLA is
$n_{\text{decoder}} \times (d_c + d^R_h) \times \mathcal{L}_{\text{output}}$
For DeepSeek-V2, the default setting is $d^R_h = \frac{d_h}{2}$, $d_c = 4d_h$ and $n_h=128$,
so the compress factor of kv-cache compared to MHA is
$
\frac{S_{\texttt{MHA}}}{S_{\texttt{MLA}}}
= \frac{2 n_h d_h}{d_c + d^R_h}
= \frac{2 n_h d_h}{\frac{9}{2} d_h}
= \frac{4}{9} n_h
\approx 56.9
$
FlashMLA